
Приветствуем Вас на портале кафедры "Компьютерные системы и сети" МГТУ им. Н.Э.Баумана
Кафедра «Компьютерные системы и сети», одна из ведущих кафедр факультета «Информатика и системы управления» МГТУ им. Н.Э. Баумана. На кафедре накоплен богатый научный и педагогический потенциал, работает коллектив опытных преподавателей, создана уникальная и современная лабораторная база, функционируют лаборатории Искусственного интеллекта, Интернета вещей, Компьютерных систем и ускорения вычислений, Облачных технологий, Сетевая лаборатория.

Во время обучения на кафедре вы изучите наиболее востребованные на рынке языки программирования.
В программе подготовки бакалавров предусмотрено изучения языков программирования C#, C/C++, JavaScript, Ruby, Python, языков верстки CSS и HTML, языки Assembler микропроцессоров x86 и микроконтроллеров Atmel. В ходе курсового проектирования на 2-м курсе бакалавриата студенты учатся теории и практике разработки программных систем.

Вы получите уникальные знания и навыки разработки микропроцессорных систем и систем на кристалле.
Вы пройдете путь, начиная с азов дисциплин "Электротехника" и "Электроника", до реализации собственных проектов в курсах "Микропроцессорные системы" и "Организация ЭВМ и систем".

Мы используем самое современное оборудование для проведения практических занятий на кафедре.
Кафедра предоставляет бесплатный доступ ко всему необходимому программному обеспечению, средствам проектирования и оборудованию.

Студентам предоставляется доступ к оборудованию для проектирования.
Мы предоставляем комплекты для индивидуального освоения интересующих вас технологий, датчики, средства сопряжения, беспроводные интерфейсы, средства отладки, актуаторы и многое другое. Мы поддержим ваши разработки не только оборудованием, но и консультациями с опытными специалистами, и даже поможем найти спонсоров и заказчиков ваших разработок.

За последние 5 лет на кафедре были разработаны более 100 студенческих проектов в области Искусственного интеллекта, Промышленного Интернета вещей, обработки Больших данных, встраиваемых систем.
В содружестве с Первым МГМИ им. И.М.Сеченова и ФМБА РФ мы разрабатываем проекты ИИ в области медицины. Совместно с МВД РФ мы разрабатываем системы по борьбе с правонарушениями. Мы помогаем студентам в продвижении собственных проектов у индустриальных партнеров.
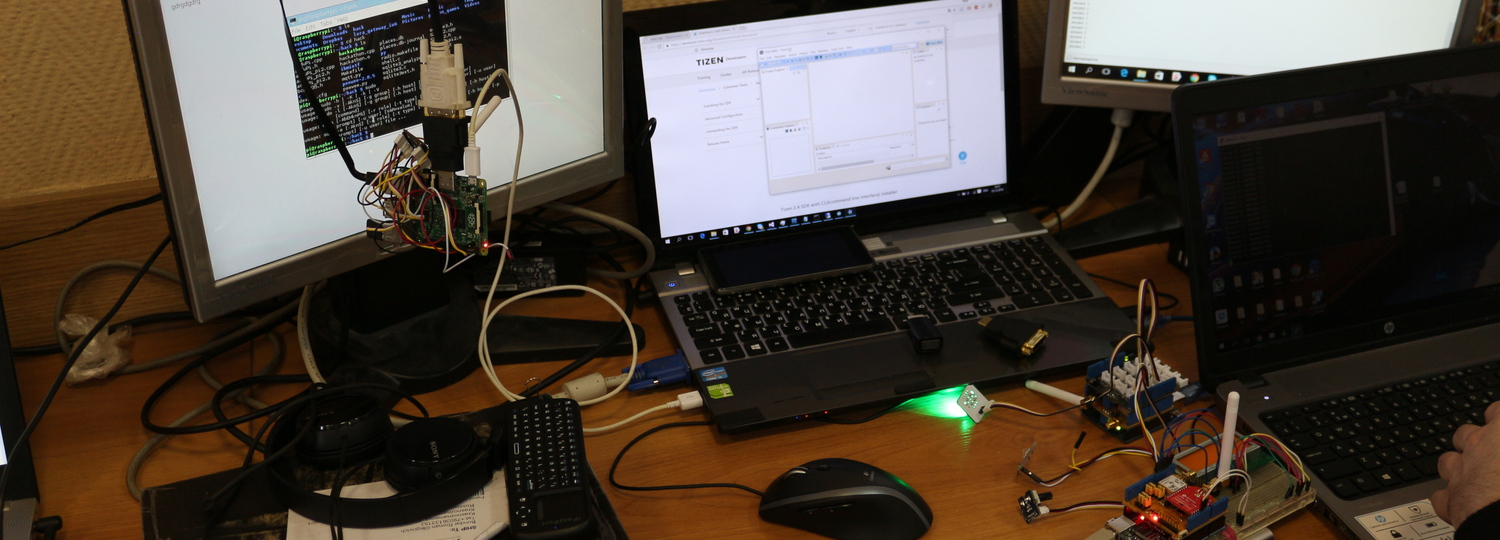
Мы учим студентов не только применять средства вычислительной техники, но и разрабатывать их.
Мы используем самые современные технологии на основе FPGA для создания ускорителей вычислений и реализации проектов ИИ. Студенты получают навыки проектирования средств ВТ на основе языков описания аппаратных средств VHDL и Verilog, и применения языков высокого уровня SystemC и С для синтеза ИС.

Мы выглядим современно! Мы постоянно обновляем оборудование и ресурсы кафедры.
Кафедра располагает современными мультимедийными аудиториями и оборудованием для проведения интерактивных занятий. На кафедре располагаются лаборатории, устроены зоны для творческой деятельности, созданы удобные консультативные зоны.

На кафедре развернуты 5 лабораторий для изучения сетевых технологий от компаний Cisco и Huawei.
Функционируют 15 стендов оборудования для изучения средств создания глобальных и корпоративных сетей, защиты компьютерных сетей, создания беспроводных сетей. На кафедре развернуто самое передовое оборудование на основе сетей WiFi6.

Лаборатория Интернета вещей
На кафедре функционирует лаборатория Промышленного Интернета вещей. Студентам предоставляется все необходимое оборудование для реализации собственных проектов IoT.
Разработка проектов ИИ
Кафедра активно занимается разработкой и внедрением проектов Искусственного интеллекта. Студентам предоставляется доступ к передовым техническим средствам для реализации собственных идей. Проводятся конкурсы студенческих проектов ИИ.

Разработка программно-аппаратных проектов
Кафедра специализируется на разработке проектов на стыке программного и аппаратного обеспечения. Это дает студентам все необходимые знания для разработки высокопроизводительных систем Интернета вещей, систем обработки Больших данных, высоконагруженных систем, встраиваемых систем, промышленных систем управления производством.

Участие в конкурсах и хакатонах
Ежегодно на кафедре "Компьютерные системы и сети" проводится студенческое соревнование проектов. Многие проекты успешно прошли путь от единичных прототипов до Startup и бизнес-проектов.
Некоторые
Значения2513
Пользователи
280
Курсы
5637
Активные элементы