Введение в язык R
Структуры данных в R
Векторы
car_name <-c("Honda","BMW","Ferrari")
car_color =c("Black","Blue","Red")
car_cc =c(2000,3400,4000)
car_name <-c("Honda","BMW","Ferrari")
#Select 1st and 2nd index from the vector
car_name[c(1,2)]
[1] "Honda" "BMW"
#Select all except 2nd index
car_name[-2]
[1] "Honda" "Ferrari"
#Select 2nd index
car_name[c(FALSE,TRUE,FALSE)]
[1] "BMW"
Матрицы
cars <-list(name =c("Honda","BMW","Ferrari"),
color =c("Black","Blue","Red"),
cc =c(2000,3400,4000))
cars
$name
[1] "Honda" "BMW" "Ferrari"
$color
[1] "Black" "Blue" "Red"
$cc
[1] 2000 3400 4000
mdat <-matrix(c(1,2,3, 11,12,13), nrow =2, ncol =3, byrow =TRUE,
dimnames =list(c("row1", "row2"),
c("C.1", "C.2", "C.3")))
#Select first two rows and all columns
mdat[1:2,]
C.1 C.2 C.3
row1 1 2 3
row2 11 12 13
#Select first columns and all rows
mdat[,1:2]
C.1 C.2
row1 1 2
row2 11 12
#Select first two rows and first column
mdat[1:2,"C.1"]
row1 row2
1 11
#Select first row and first two columns
mdat[1,1:2]
C.1 C.2
1 2
Списки
mdat <-matrix(c(1,2,3, 11,12,13), nrow =2, ncol =3, byrow =TRUE,
dimnames =list(c("row1", "row2"),
c("C.1", "C.2", "C.3")))
mdat
C.1 C.2 C.3
row1 1 2 3
row2 11 12 13
cars <-list(name =c("Honda","BMW","Ferrari"),
color =c("Black","Blue","Red"),
cc =c(2000,3400,4000))
#Select the second list with cars
cars[2]
$color
[1] "Black" "Blue" "Red"
#select the first element of second list in cars
cars[[c(2,1)]]
[1] "Black"
Фреймы данных расширяют возможности матриц, позволяя хранить разнородные типы данных. Во фрейме данных можно хранить символьные, числовые и факторные переменные в разных столбцах одного фрейма данных. Практически в каждой задаче анализа данных, связанной со строками и столбцами данных, фрейм данных является естественным выбором для хранения данных. В следующем примере показано, как числовые и факторные столбцы хранятся в одном фрейме данных.
L3 <-LETTERS[1:3]
fac <-sample(L3, 10, replace =TRUE)
df <-data.frame(x =1, y =1:10, fac = fac)
class(df$x)
[1] "numeric"
class(df$y)
[1] "integer"
class(df$fac)
[1] "factor"
L3 <-LETTERS[1:3]
fac <-sample(L3, 10, replace =TRUE)
df <-data.frame(x =1, y =1:10, fac = fac)
#Select all the rows where fac column has a value "A"
df[df$fac=="A",]
x y fac
2 1 2 A
5 1 5 A
6 1 6 A
7 1 7 A
8 1 8 A
10 1 10 A
#Select first two rows and all columns
df[c(1,2),]
x y fac
1 1 1 B
2 1 2 A
#Select first column as a vector
df$x
[1] 1 1 1 1 1 1 1 1 1 1
Функции
nthroot <-function(num, nroot) {
return (num ^(1/nroot))
}
nthroot(8,3)
[1] 2
Чтение данных из файла формата csv
read.csv("employees.csv", header =TRUE, sep =",")
Code First.Name Last.Name Salary.US.Dollar.
1 15421 John Smith 10000
2 15422 Peter Wolf 20000
3 15423 Mark Simpson 30000
4 15424 Peter Buffet 40000
5 15425 Martin Luther 50000
Чтение данных из файла формата xlsx
library(xlsx)
read.xlsx("employees.xlsx",sheetName ="Sheet1")
Code First.Name Last.Name Salary.US.Dollar.
1 15421 John Smith 10000
2 15422 Peter Wolf 20000
3 15423 Mark Simpson 30000
4 15424 Peter Buffet 40000
5 15425 Martin Luther 50000
Пакет XML и plyr в R можно использовать этот файл в data.frame следующим образом:
library(XML)
library(plyr)
xml:data <-xmlToList("marathon.xml")
#Excluding "description" from print
ldply(xml:data, function(x) { data.frame(x[!names(x)=="description"]) } )
.id name age
1 athletes Mike 25
2 athletes Usain 29
awards titles
1 \n Two time world champion. Currently, worlds No. 3\n 6
2 \n Five time world champion. Currently, worlds No. 1\n 17
Первичный анализ данных Initial Data Analysis (IDA)
emp <-read.csv("employees.csv", header =TRUE, sep =",")
str(emp)
'data.frame': 5 obs. of 4 variables:
$ Code : int 15421 15422 15423 15424 15425
$ First.Name : Factor w/ 4 levels "John","Mark",..: 1 4 2 4 3
$ Last.Name : Factor w/ 5 levels "Buffet","Luther",..: 4 5 3 1 2
$ Salary.US.Dollar.: int 10000 20000 30000 40000 50000
#Manually overriding the naming convention
names(emp) <-c('Code','First Name','Last Name', 'Salary(US Dollar)')
# Look at the variable name
emp
Code First Name Last Name Salary(US Dollar)
1 15421 John Smith 10000
2 15422 Peter Wolf 20000
3 15423 Mark Simpson 30000
4 15424 Peter Buffet 40000
5 15425 Martin Luther 50000
# Now let's clean it up using make.names
names(emp) <-make.names(names(emp))
# Look at the variable name after cleaning
emp
Code First.Name Last.Name Salary.US.Dollar.
1 15421 John Smith 10000
2 15422 Peter Wolf 20000
3 15423 Mark Simpson 30000
4 15424 Peter Buffet 40000
5 15425 Martin Luther 50000
#Find duplicates
table(emp$Code)
15421 15422 15423 15424 15425
1 1 1 1 1
#Find common names
table(emp$First.Name)
John Mark Martin Peter
1 1 1 2
merge(emp, emp_qual, by ="Code")
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
merge(emp, emp_qual, by ="Code", all.x =TRUE)
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15424 Peter Buffet 40000 <NA>
5 15425 Martin Luther 50000 <NA>
merge(emp, emp_qual, by ="Code", all.y =TRUE)
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15426 <NA> <NA> NA PhD
5 15429 <NA> <NA> NA Phd
merge(emp, emp_qual, by ="Code", all =TRUE)
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15424 Peter Buffet 40000 <NA>
5 15425 Martin Luther 50000 <NA>
6 15426 <NA> <NA> NA PhD
7 15429 <NA> <NA> NA Phd
library(dplyr)
inner_join(emp, emp_qual, by ="Code")
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
left_join(emp, emp_qual, by ="Code")
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15424 Peter Buffet 40000 <NA>
5 15425 Martin Luther 50000 <NA>
Right_join(emp, emp_qual, by ="Code")
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15426 <NA> <NA> NA PhD
5 15429 <NA> <NA> NA Phd
Full_join(emp, emp_qual, by ="Code",)
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15424 Peter Buffet 40000 <NA>
5 15425 Martin Luther 50000 <NA>
6 15426 <NA> <NA> NA PhD
7 15429 <NA> <NA> NA Phd
Очистка данных
Корректировка переменных типа factor
employees_qual <-read.csv("employees_qual.csv")
#Inconsistent
employees_qual
Code Qual
1 15421 Masters
2 15422 PhD
3 15423 PhD
4 15426 PhD
5 15429 Phd
employees_qual$Qual =as.character(employees_qual$Qual)
employees_qual$Qual <-ifelse(employees_qual$Qual %in%c("Phd","phd","PHd"),
"PhD", employees_qual$Qual)
#Corrected
employees_qual
Code Qual
1 15421 Masters
2 15422 PhD
3 15423 PhD
4 15426 PhD
5 15429 PhD
Обработка NA
emp <-read.csv("employees.csv")
employees_qual <-read.csv("employees_qual.csv")
#Correcting the inconsistency
employees_qual$Qual =as.character(employees_qual$Qual)
employees_qual$Qual <-ifelse(employees_qual$Qual %in%c("Phd","phd","PHd"),
"PhD", employees_qual$Qual)
#Store the output from right_join in the variables impute_salary
impute_salary <-right_join(emp, employees_qual, by ="Code")
#Calculate the average salary for each Qualification
ave_age <-ave(impute_salary$Salary.US.Dollar., impute_salary$Qual,
FUN = function(x) mean(x, na.rm =TRUE))
#Fill the NAs with the average values
impute_salary$Salary.US.Dollar. <-ifelse(is.na(impute_salary$Salary.
US.Dollar.), ave_age, impute_salary$Salary.US.Dollar.)
impute_salary
Code First.Name Last.Name Salary.US.Dollar. Qual
1 15421 John Smith 10000 Masters
2 15422 Peter Wolf 20000 PhD
3 15423 Mark Simpson 30000 PhD
4 15426 <NA> <NA> 25000 PhD
5 15429 <NA> <NA> 25000 PhD
Выборка показателей развития и их значений для страны Зимбабве за 1995 и 1998 годы:
library(data.table)
WDI_Data <-fread("WDI_Data.csv", header =TRUE, skip =333555, select
=c(3,40,43))
setnames(WDI_Data, c("Dev_Indicators", "1995","1998"))
WDI_Data <-WDI_Data[c(1,3),]
#Development indicators (DI):
WDI_Data[,"Dev_Indicators", with =FALSE]
Dev_Indicators
1: Women's share of population ages 15+ living with HIV (%)
2: Youth literacy rate, population 15-24 years, female (%)
DI value for the years 1995 and 1998:
WDI_Data[,2:3, with =FALSE]
1995 1998
1: 56.02648 56.33425
2: NA NA
library(tidyr)
gather(WDI_Data,Year,Value, 2:3)
Dev_Indicators Year Value
1: Women's share of population ages 15+ living with HIV (%) 1995 56.02648
2: Youth literacy rate, population 15-24 years, female (%) 1995 NA
3: Women's share of population ages 15+ living with HIV (%) 1998 56.33425
4: Youth literacy rate, population 15-24 years, female (%) 1998 NA
Предварительный анализ данных Exploratory Data Analysis (EDA)
marathon <-read.csv("marathon.csv")
summary(marathon)
Id Type Finish_Time
Min. : 1.00 First-Timer :17 Min. :1.700
1st Qu.:13.25 Frequents :19 1st Qu.:2.650
Median :25.50 Professional:14 Median :4.300
Mean :25.50 Mean :4.651
3rd Qu.:37.75 3rd Qu.:6.455
Max. :50.00 Max. :9.000
quantile(marathon$Finish_Time, 0.25)
25%
2.65
quantile(marathon$Finish_Time, 0.25)
25%
2.65
Второй квартиль (медиана):
quantile(marathon$Finish_Time, 0.5)
50%
4.3
median(marathon$Finish_Time)
[1] 4.3
Третий квартиль:
quantile(marathon$Finish_Time, 0.75)
75%
6.455
quantile(marathon$Finish_Time, 0.75, names =FALSE)
-quantile(marathon$Finish_Time, 0.25, names =FALSE)
[1] 3.805
mean(marathon$Finish_Time)
[1] 4.6514
Frequency plot (частотное распределение дискретной или непрерывной переменной)
plot(marathon$Type, xlab ="Marathoners Type", ylab ="Number of
Marathoners")
boxplot(Finish_Time ~Type,data=marathon, main="Marathon Data", xlab="Type of
Marathoner", ylab="Finish Time")
Дисперсия, среднеквадратичное отклонение, среднее арифметическое
mean(marathon$Finish_Time)
[1] 4.6514
var(marathon$Finish_Time)
[1] 4.342155
sd(marathon$Finish_Time)
[1] 2.083784
Рассматривая значения среднего и стандартного отклонения, можно сказать, что в среднем
время финиша марафонцев составляет 4.65 +/- 2.08 часов. Кроме того, из следующего фрагмента кода легко заметить, что у каждого типа бегунов своя скорость бега и, следовательно, разное время финиша.
tapply(marathon$Finish_Time,marathon$Type, mean)
First-Timer Frequents Professional
7.154118 4.213158 2.207143
tapply(marathon$Finish_Time,marathon$Type, sd)
First-Timer Frequents Professional
0.8742358 0.5545774 0.3075068
Ассиметрия
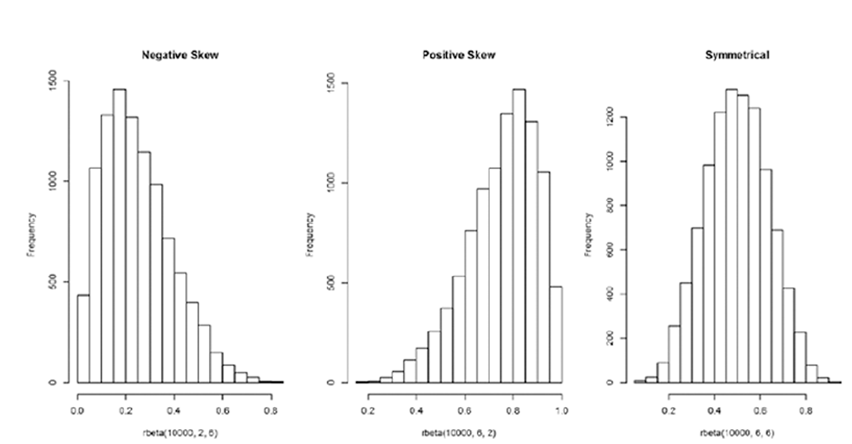
Поскольку дисперсия является мерой разброса, асимметрия измеряет асимметрию относительно среднего значения распределения вероятностей случайной величины. В целом, как следует из стандартного определения, можно наблюдать два типа асимметрии:
- отрицательное смещение: левый хвост длиннее; основная часть распределения сосредоточена справа. Распределение называется левосторонним, левохвостым или смещенным влево.
- положительное смещение: правый хвост длиннее; основная часть распределения сосредоточена слева. Говорят, что распределение является правосторонним, прямохвостым или смещенным вправо.
library("moments")
par(mfrow=c(1,3), mar=c(5.1,4.1,4.1,1))
# Negative skew
hist(rbeta(10000,2,6), main ="Negative Skew" )
skewness(rbeta(10000,2,6))
[1] 0.7166848
# Positive skew
hist(rbeta(10000,6,2), main ="Positive Skew")
skewness(rbeta(10000,6,2))
[1] -0.6375038
# Symmetrical
hist(rbeta(10000,6,6), main ="Symmetrical")
skewness(rbeta(10000,6,6))
[1] -0.03952911
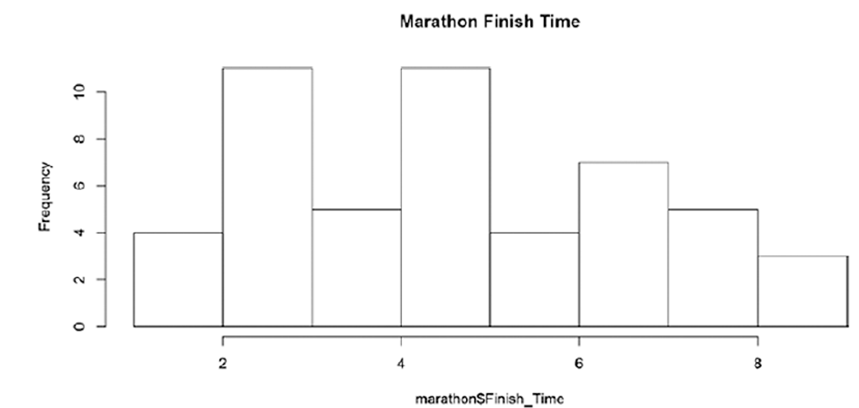
hist(marathon$Finish_Time, main ="Marathon Finish Time")
skewness(marathon$Finish_Time)
[1] 0.3169402
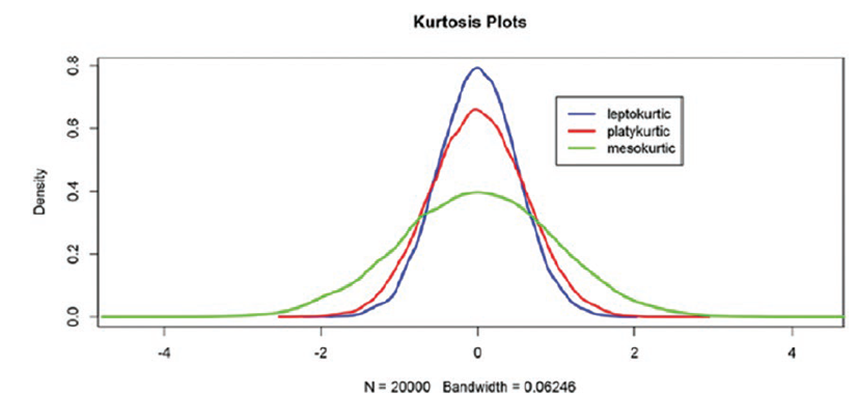
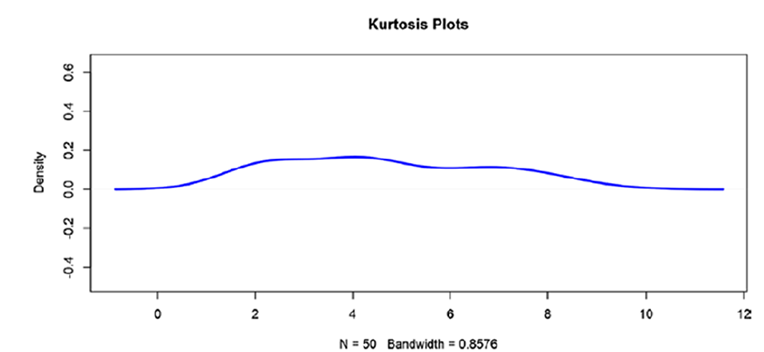
Эксцесс (Kurtosis)в статистике
- Мезокуртическое распределение: распределения со значением эксцесса, близким к 3, что означает, что в предыдущей формуле слагаемое перед 3 становится равным 0, стандартное нормальное распределение со средним значением 0 и стандартным отклонением 1.
- Платокуртическое распределение: распределения со значением эксцесса < 3. Сравнительно более низкий пик и более короткие хвосты по сравнению с нормальным распределением.
- Лептокуртическое распределение: распределения со значением эксцесса > 3. Сравнительно более высокий пик и более длинные хвосты по сравнению с нормальным распределением.
#leptokurtic
set.seed(2)
random_numbers <-rnorm(20000,0,0.5)
plot(density(random_numbers), col ="blue", main ="Kurtosis Plots", lwd=2.5,
asp =4)
kurtosis(random_numbers)
[1] 3.026302
#platykurtic
set.seed(900)
random_numbers <-rnorm(20000,0,0.6)
lines(density(random_numbers), col ="red", lwd=2.5)
kurtosis(random_numbers)
[1] 2.951033
#mesokurtic
set.seed(3000)
random_numbers <-rnorm(20000,0,1)
lines(density(random_numbers), col ="green", lwd=2.5)
kurtosis(random_numbers)
[1] 3.008717
legend(1,0.7, c("leptokurtic", "platykurtic","mesokurtic" ),
lty=c(1,1),
lwd=c(2.5,2.5),col=c("blue","red","green"))
plot(density(as.numeric(marathon$Finish_Time)), col ="blue", main
="KurtosisPlots", lwd=2.5, asp =4)
kurtosis(marathon$Finish_Time)
[1] 1.927956
Использование data table
Быстрая агрегация больших объемов данных (например, 100 ГБоперативной памяти), быстрое упорядоченное объединение, быстрое добавление / изменение / удаление столбцов по группам, списки столбцов и быстрое средство чтения файлов (fread).
https://www.kaggle.com/code/mhassell/ccfraud
library(data.table)
data <-fread("ccFraud.csv",header=T, verbose =FALSE, showProgress =FALSE)
str(data)
Classes 'data.table' and 'data.frame': 10000000 obs. of 9 variables:
$ custID : int 1 2 3 4 5 6 7 8 9 10 ...
$ gender : int 1 2 2 1 1 2 1 1 2 1 ...
$ state : int 35 2 2 15 46 44 3 10 32 23 ...
$ cardholder : int 1 1 1 1 1 2 1 1 1 1 ...
$ balance : int 3000 0 0 0 0 5546 2000 6016 2428 0 ...
$ numTrans : int 4 9 27 12 11 21 41 20 4 18 ...
$ numIntlTrans: int 14 0 9 0 16 0 0 3 10 56 ...
$ creditLine : int 2 18 16 5 7 13 1 6 22 5 ...
$ fraudRisk : int 0 0 0 0 0 0 0 0 0 0 ...
- attr(*, ".internal.selfref")=<externalptr>
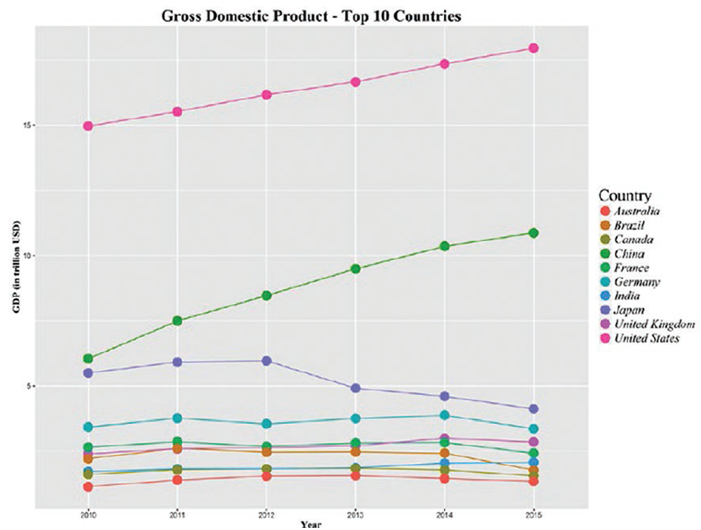
Визуализация данных в R:
library(reshape)
library(ggplot2)
GDP <-read.csv("Dataset/Total GDP 2015 Top 10.csv")
names(GDP) <-c("Country", "2010","2011","2012","2013","2014","2015")
GDP_Long_Format <-melt(GDP, id="Country")
names(GDP_Long_Format) <-c("Country", "Year","GDP_USD_Trillion")
ggplot(GDP_Long_Format, aes(x=Year, y=GDP_USD_Trillion, group=Country)) +
geom_line(aes(colour=Country)) +
geom_point(aes(colour=Country),size =5) +
theme(legend.title=element_text(family="Times",size=20),
legend.text=element_text(family="Times",face ="italic",size=15),
plot.title=element_text(family="Times", face="bold", size=20),
axis.title.x=element_text(family="Times", face="bold", size=12),
axis.title.y=element_text(family="Times", face="bold", size=12)) +
xlab("Year") +
ylab("GDP (in trillion USD)") +
ggtitle("Gross Domestic Product - Top 10 Countries")
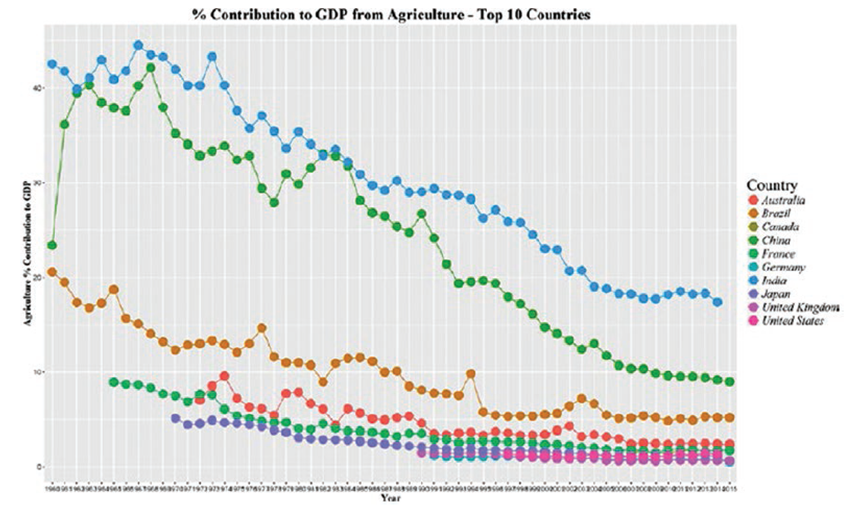
# Agriculture
Agri_GDP <-read.csv("Dataset/Agriculture - Top 10 Country.csv")
Agri_GDP_Long_Format <-melt(Agri_GDP, id ="Country")
names(Agri_GDP_Long_Format) <-c("Country", "Year", "Agri_Perc")
Agri_GDP_Long_Format$Year <-substr(Agri_GDP_Long_Format$Year,
2,length(Agri_GDP_Long_Format$Year))
Apply the ggplot2() options to create plots as follows:
ggplot(Agri_GDP_Long_Format, aes(x=Year, y=Agri_Perc, group=Country)) +
geom_line(aes(colour=Country)) +
geom_point(aes(colour=Country),size =5) +
theme(legend.title=element_text(family="Times",size=20),
legend.text=element_text(family="Times",face ="italic",size=15),
plot.title=element_text(family="Times", face="bold", size=20),
axis.title.x=element_text(family="Times", face="bold", size=12),
axis.title.y=element_text(family="Times", face="bold", size=12)) +
xlab("Year") +
ylab("Agriculture % Contribution to GDP") +
ggtitle("Agriculture % Contribution to GDP - Top 10 Countries")
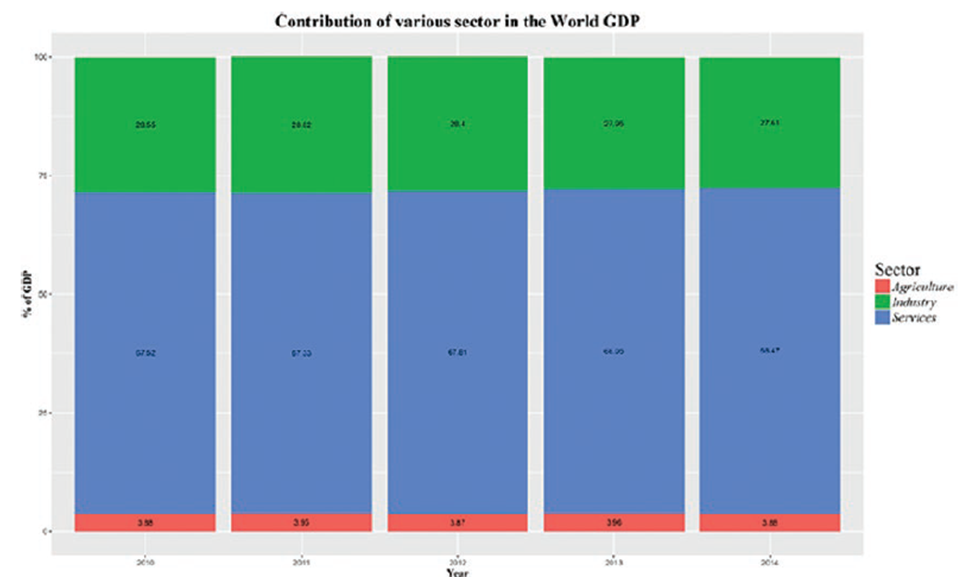
Столбчатые диаграммы с группировкой - способ показать состав различных категорий, составляющих определенную переменную. Здесь, в примере на рис. 4-5, легко увидеть, какой процентный вклад вносит каждый из этих секторов в общий мировой ВВП.
library(plyr)
World_Comp_GDP <-read.csv("World GDP and Sector.csv")
World_Comp_GDP_Long_Format <-melt(World_Comp_GDP, id ="Sector")
names(World_Comp_GDP_Long_Format) <-c("Sector", "Year", "USD")
World_Comp_GDP_Long_Format$Year <-substr(World_Comp_GDP_Long_Format$Year,
2,length(World_Comp_GDP_Long_Format$Year))
World_Comp_GDP_Long_Format_Label <-ddply(World_Comp_GDP_Long_Format, .(Year),
transform, pos =cumsum(USD) -(0.5 *USD))
ggplot(World_Comp_GDP_Long_Format_Label, aes(x = Year, y = USD, fill =
Sector)) +
geom_bar(stat ="identity") +
geom_text(aes(label = USD, y = pos), size =3) +
theme(legend.title=element_text(family="Times",size=20),
legend.text=element_text(family="Times",face ="italic",size=15),
plot.title=element_text(family="Times", face="bold", size=20),
axis.title.x=element_text(family="Times", face="bold", size=12),
axis.title.y=element_text(family="Times", face="bold", size=12)) +
xlab("Year") +
ylab("% of GDP") +
ggtitle("Contribution of various sector in the World GDP")
library(reshape2)
library(ggplot2)
Population_Working_Age <-read.csv("Age dependency ratio - Top 10 Country.csv")
Population_Working_Age_Long_Format <-melt(Population_Working_Age, id
="Country") names(Population_Working_Age_Long_Format) <-c("Country",
"Year", "Wrk_Age_Ratio") Population_Working_Age_Long_Format$Year
<-substr(Population_Working_Age_ Long_Format$Year, 2,length(Population_
Working_Age_Long_Format$Year))
ggplot(Population_Working_Age_Long_Format, aes(x=Year, y=Wrk_Age_Ratio,
group=Country)) +
geom_line(aes(colour=Country)) +
geom_point(aes(colour=Country),size =5) +
theme(legend.title=element_text(family="Times",size=20),
legend.text=element_text(family="Times",face ="italic",size=15),
plot.title=element_text(family="Times", face="bold", size=20),
axis.title.x=element_text(family="Times", face="bold", size=12),
axis.title.y=element_text(family="Times", face="bold", size=12)) +
xlab("Year") +
ylab("Working age Ratio") +
ggtitle("Working age Ratio - Top 10 Countries")
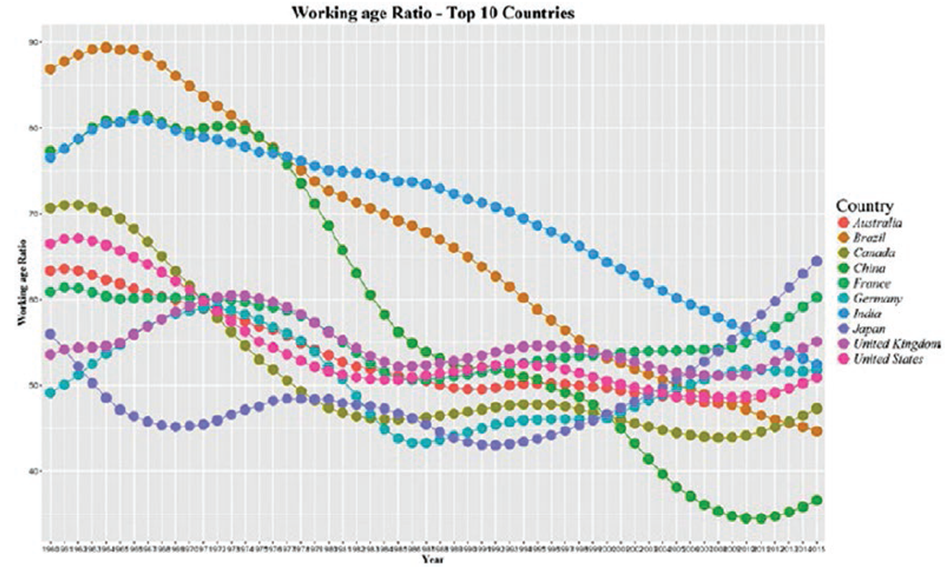
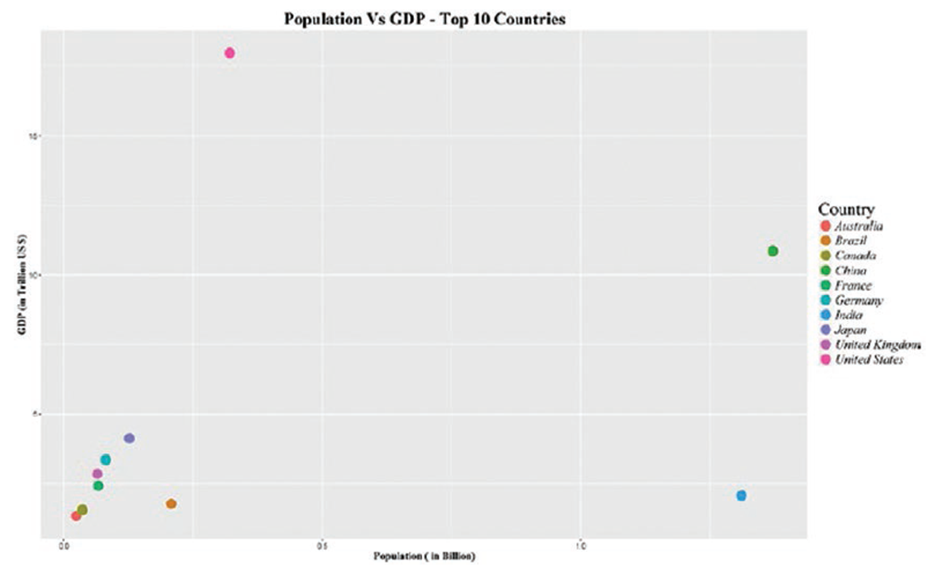
Диаграмма рассеяния (ScetterPlot)
library(reshape2)
library(ggplot2)
GDP_Pop <-read.csv("GDP and Population 2015.csv")
ggplot(GDP_Pop, aes(x=Population_Billion, y=GDP_Trilion_USD))+
geom_point(aes(color=Country),size =5) +
theme(legend.title=element_text(family="Times",size=20),
legend.text=element_text(family="Times",face ="italic",size=15),
plot.title=element_text(family="Times", face="bold", size=20),
axis.title.x=element_text(family="Times", face="bold", size=12),
axis.title.y=element_text(family="Times", face="bold", size=12)) +
xlab("Population ( in Billion)") +
ylab("GDP (in Trillion US $)") +
ggtitle("Population Vs GDP - Top 10 Countries")