Методические указания к лр. 3
install.packages("MASS")
library(MASS)
#загрузка исходных данных (набора Boston) из пакета MASS
|
Параметр |
Значение |
|
crim |
уровень преступности на душу населения по городам |
|
zn
|
доля земли под жилую застройку, (под участки площадью более 25000 кв. футов) |
|
indus |
доля акров, не связанных с розничной торговлей, на город |
|
chas |
Фиктивная переменная Charles River (= 1, если участок граничит с рекой; 0 в противном случае) |
|
nox |
концентрация оксидов азота (частей на 10 млн) |
|
rm |
среднее количество комнат в доме |
|
age |
доля занятых владельцами единиц, построенных до 1940 года |
|
dis
|
средневзвешенное расстояние до пяти бостонских центров занятости |
|
rad |
индекс доступности радиальных автомобильных дорог |
|
tax
|
полная ставка налога на имущество за каждые 10 000 долларов стоимости |
|
ptratio |
соотношение учеников и учителей по городам |
|
black |
|
|
lstat |
более низкий статус населения (в процентах) |
|
medv
|
медианная стоимость домов, занимаемых владельцами, составляет 1000 долларов |
data(Boston)
#Вывод первых 5 строк набора Boston
head(Boston)
#Вывод признака indus перед нормализацией
hist(Boston$indus)
#масштабирование (нормализация) данных, необходимая для исключения
#преобладающего влияния какого-либо параметра на результат прогноза
#метод масштабирования – min-max Normalization
Boston$indus<- (Boston$indus - min(Boston$indus)) / (max(Boston$indus) - min(Boston$indus))
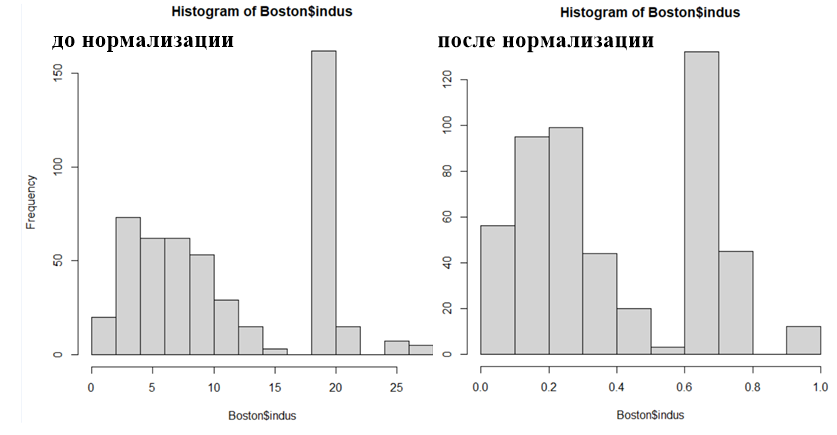
Рис. 1. Пример масштабирования параметра indus обучающей выборки |
#выполняем
масштабирование остальных параметров обучающей выборки (кроме <span lang="EN-US">chas</span>)
hist(Boston$indus)
#делим данные на обучающую и тестовую выборки
set.seed(222)
inp <- sample(2, nrow(Boston), replace = TRUE, prob = c(0.7, 0.3))
train.boston <- Boston[inp==1, ]
head(train.boston)
test.boston <- Boston[inp==2, ]
head(test.boston)
#настройка нейронной
сети
install.packages("neuralnet")
library(neuralnet)
set.seed(333)
#паремтры функции neuralnet
- formula - символьное описание модели, которая должна быть установлена. По умолчанию не указано.
- data - фрейм данных, содержащий переменные, указанные в формуле. По умолчанию не указано.
- hidden - вектор, определяющий количество скрытых слоев и скрытых нейронов в каждом слое. Например, вектор (3,2,1) создает нейронную сеть с тремя скрытыми слоями, первый
из которых состоит из трех, второй - из двух, а третий - из одного скрытого нейрона. По умолчанию:1.
- threshold - целое число, задающее порог для частных производных функции ошибки в качестве критерия остановки. По умолчанию: 0,01.
- rep - количество повторений в тренировочном процессе. По умолчанию: 1.
- startweights - вектор, содержащий заданные начальные значения для весов. По умолчанию: случайные числа, полученные из стандартного нормального распределения
algorithm - алгоритм - строка, содержащая тип алгоритма. Возможные значения: "backprop", "rprop+", "rprop-", "sag" или "slr". "backprop" относится к традиционному обратному распространению, "rprop+" и "rprop-" относятся к устойчивому обратному распространению с отслеживанием веса и без него, а "sag" и "slr" относятся к модифицированному глобально конвергентному алгоритму (grprop). "sag" и "slr" определяют скорость обучения , которая изменяется в соответствии со всеми остальными параметрами. "sag" относится к наименьшей абсолютной производной, "slr" - к наименьшей скорости обучения. По умолчанию: "rprop+"
- err.fct - дифференцируемая функция обнаружения ошибок. Можно использовать строки "sse" и "ce", которые относятся к "сумме квадратов ошибок" и "перекрестной энтропии’. По умолчанию: "sse"
- act.fct - дифференцируемая функция активации. Строки "logistic" и "tanh" возможны для логистической функции и касательной гиперболы. По умолчанию: "logistic"
- linear.output - логический. Если act.fct не следует применять к выходным нейронам, значение linear.output должно быть ИСТИННЫМ. По умолчанию: TRUE
- likelihood - вероятность, логическая. Если функция ошибки равна отрицательной логарифмической функции правдоподобия, вероятность должна быть ИСТИННОЙ. Затем будут рассчитаны информационный критерий Акайке (AIC, Akaike, 1973) и информационный критерий Байеса (BIC, Schwarz, 1978). По умолчанию: FALSE
- exclude - вектор или матрица, указывающая веса, которые должны быть исключены из обучения. Матрица с n строками и тремя столбцами исключит n весов, где первый столбец указывает уровень, второй столбец - входной нейрон веса, а третий нейрон - выходной нейрон веса. Если задано в виде вектора, то должна быть известна точная нумерация. Нумерацию можно проверить, используя предоставленный график или сохраненные начальные веса. По умолчанию: NULL
- constant.weights - вектор, определяющий значения весов, которые исключаются из обучения и рассматриваются как фиксированные. По умолчанию: NULL
n <-neuralnet(chas~crim
+ zn + indus + nox + rm + age + dis + rad + tax + ptratio + black + lstat +
medv, data = train.boston,
hidden = 15,
#количество скрытых нейронов (вершин) в каждом слое
err.fct = "ce",
linear.output = FALSE,
lifesign = 'full',
rep = 2,
#количество повторений для обучения нейронной сети
algorithm = "rprop+", stepmax = 100000)
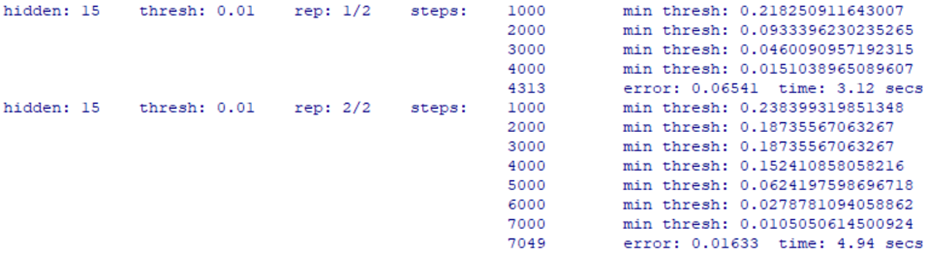
Рис. 2. Результаты первой и второй итераций
# визуализация построенной нейронной сети (рис. 2), черные линии – веса,
# синие – смещения
Первая итерация дает ошибку (рис. 2): 0.06541, вторая – 0.01633. Для дальнейших вычислений будем использовать вторую итерацию.
plot(n, rep = 2)# может быть здесь rep=2
|
Рис. 3. Визуализация построенной нейронной сети |
# генерация ошибки нейронной сети по весам между входом, скрытыми слоями и выходом
n$result.matrix

Рис. 4. Фрагмент результатов генерации ошибки
# функция subset используется для исключения зависимой переменной из тестовой выборки
# (рис. 5)
test <- subset(test.boston, select = c("crim","zn","indus","nox","rm","age","dis","rad","tax","ptratio","black","lstat","medv"))
head (test)
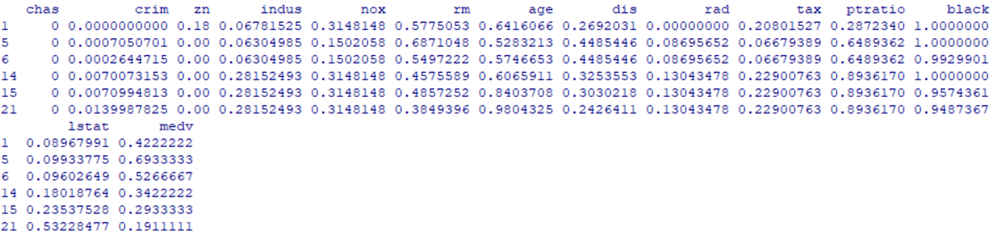 #
#
Рис. 5. Результат работы функции subset
#Функция compute создает переменную прогноза
n.results <- compute (n, test)
# переменная result содержит сводную таблицу прогнозируемых и фактических результатов
results <- data.frame (actual = test.boston $ chas, prediction = n.results $ net.result)
results
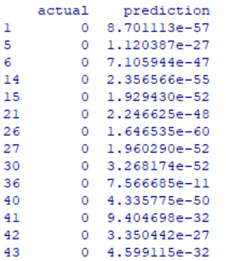
Рис. 6. Фрагмент сводной таблицы прогнозируемых и фактических результатов
# составление матрицы путаницы
# функция sapply округляет результаты
roundres<-sapply(results,round,digits=0)
roundres1 =data.frame(roundres)
attach(roundres1)
#вывод матрицы путаницы*(см. примечание) (рис. 7)
table(actual,prediction)
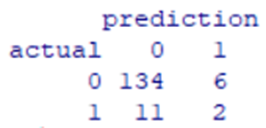
Рис. 7. Фрагмент сводной таблицы прогнозируемых и фактических результатов
Метрика accuracy составляет 0, 89 или 89%.
Этот показатель может быть улучшен ручным подбором количества скрытых слоев и количества нейронов в каждом из них.
В таблице 6.7 приведены метрики проведенной классификации:
|
Таблица 1. Метрики проведенной классификации |
|
Метрики |
accuracy |
error-rate |
TP rate |
FP rate (recall) |
TN rate |
precision |
F-measure |
|
|
0.89 |
0.11 |
0.95 |
0.85 |
0.15 |
0.92 |
0.88 |
#Еще один вариант вывода матрицы путаницы
#Устанавливаем библиотеку caret
install.packages("caret")
library(caret)
confmatr <- table(prediction, actual)
confusionMatrix(confmatr)1. Матрица неточностей (матрица путаницы) (confusion matrix) – таблица, в которой строки являются реально существующие объекты некоторого класса. Столбцы таблицы – прогнозируемые объекты некоторого класса. На основе матрицы может быть вычислена метрика accuracy. Например,
Имеется 12 изображений автомобилей. Из них 7 – обычные автомобили, 5 – болиды. Классификатор правильно определил 5 обычных автомобилей из 7, а два были ошибочно определены, как болиды. Из 5 болидов классификатор верно распознал 3 болида и 2 были распознан, как обычный автомобиль. В матрице неточности все примеры, принадлежащие одному классу из двух, считаются положительными (positive), а все пример, принадлежащие другому классу – отрицательными (negative). Значения за пределами диагонали рассматриваются, как ошибки. В примере 2 обычных автомобиля и 2 болида были неправильно распознаны. То есть, из 12 изображений 4 изображения распознаны с ошибками, а 8 – правильно.
|
Таблица 6.1. Матрица неточностей |
|
Фактический класс
Прогнозируемый класс |
Обычный автомобиль |
Болид |
|
Обычный автомобиль |
5 (TP) |
2 (FN) |
|
Болид |
2 (FP) |
3 (TN) |
2. Accuracy (точность) – метрика бинарной классификации - доля правильных ответов модели. Измеряется отношением числа правильных ответов модели, к числу всех объектов. Эта метрика измеряет количество верно классифицированных объектов относительно общего количества всех объектов. Метрику не следует использовать для несбалансированных классов, (большое количество экземпляров одного класса и небольшое другого класса)
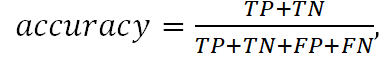
где
- TP - количество положительных примеров, определенных правильно
- TN - количество отрицательных примеров, определенных правильно
- FP - количество положительных примеров, определенных ошибочно
- FN - количество отрицательных примеров, определенных ошибочно
Например, из 100 писем, не являющихся спамом, 90 классификатор определил верно ( ), и из 10 спам-писем, 5 классификатор определил верно
3. TP rate (чувствительность) или recall (эффективность) – процент верно классифицированных объектов рассматриваемого класса:
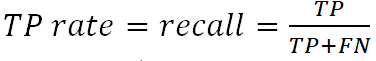
4. FP rate – количество объектов, другого класса, ошибочно распознанных, как объекты рассматриваемого класса:
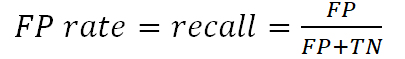
5. TN rate (специфичность (specificity)) – количество объектов, другого класса, ошибочно распознанных, как объекты рассматриваемого класса:
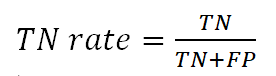
6. Precision (точность) - процент верно классифицированных объектов, отнесенных алгоритмом к рассматриваемому классу:
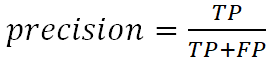
7. Error rate (misclassification error) - ошибка неправильной классификации:
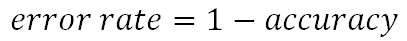
8. Среднее гармоническое precision и recall:
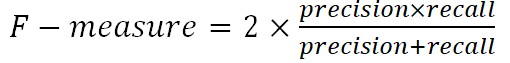
9. Корень из среднеквадратичной ошибки (RMSE) (Root Меаn Squared Error) (RMSD) или среднеквадратичное отклонение (Root Меаn Squared Deviation) - метрика регрессии, в которой каждая из ошибок возводится в квадрат, что усиливает значимость такой ошибки. В результате – можно избежать крупных ошибок.
, 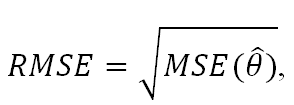
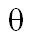 - оцениваемый параметр,
- оцениваемый параметр,
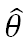 – правило для вычисления оценки.
– правило для вычисления оценки.