Случайные леса
Случайные леса
Случайный лес – это метод обучения ансамбля для классификации, регрессии и других задач, который во время обучения выполняет построение множества деревьев решений.
Правило определения съедобности гриба может быть сформулировано следующим образом (W-ширина шляпки, H-высота шляпки):
"Если 2 < W and W < 4 and H < 2 тогда «гриб съедобный», иначе «гриб ядовитый»
Это правило можно представить в виде дерева решений рис. (6.7), показанного на рисунке. Внутренние узлы дерева помечены атрибутами, листья соответствуют значению атрибута. Например, самая левая ветвь соответствует W <2. Самый левый лист означает, что гриб, попадающий в эту ветвь является ядовитым. Объект попадает в конкретный лист, если объект удовлетворяет всем условиям вдоль пути от корня к листу. Например: гриб с W = 3,0 и H = 0,9 классифицируется по этому дереву следующим образом. Начнем с корня, где условие W<2. Для данного гриба, W = 3,0, и условие в корне ложно. Тогда, переходим вправо к условию W>4. Для данного гриба это неверно, и переходим к следующему условию H>2. Гриб имеет H = 0,9, поэтому переходим к левой ветви и в конечном итоге в лист с надписью «+». Дерево определило, что гриб съедобен.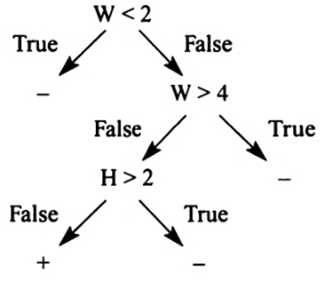
Рис. 6.7. Правило представлено в виде дерева решений
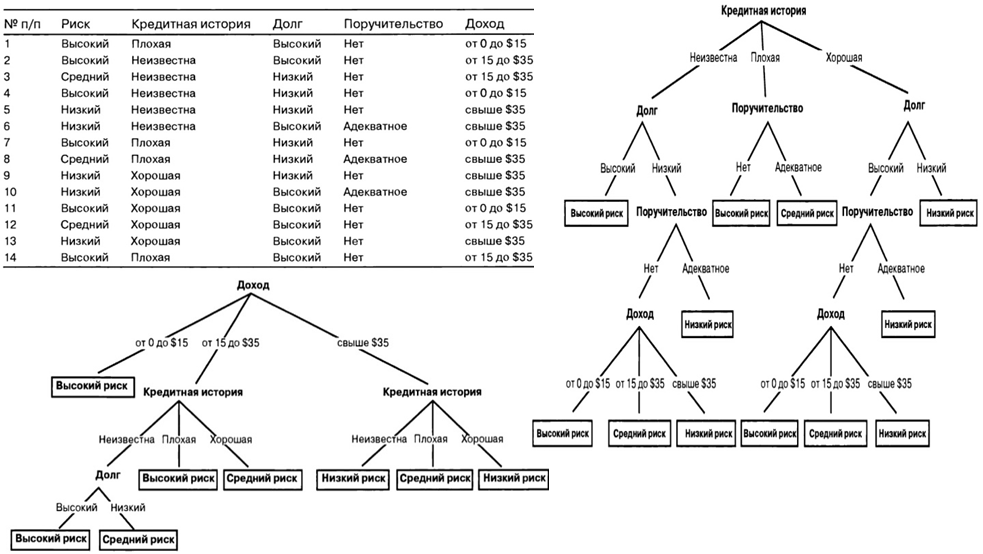
|
Рис. 6.8. Пример обучающей выборки и деревьев решений |
Под ансамблем будем понимать набор классификаторов, например, деревьев решений, прогнозы которых агрегируются для более оптимальных решений. Деревья решений строятся по случайным наборам при помощи бэггинга или бутстреп-агрегирования, что обеспечивает их отличие друг от друга. Бэггинг заключается в параллельном обучении моделей, а затем объединении их в ансамбль путем усреднения. Перед началом обучения устанавливается количество деревьев, число исходных переменных, участвующих в построении деревьев (параметров для разбиения). Таким образом, случайные леса являются ансамблиевым методом машинного обучения. Наличие фактора случайности делает невозможным контроль прогнозов деревьев, входящих в ансамбль, но случайные леса тем не менее оправдывают свое существование легкостью создания и точностью прогнозирования. Ниже приведен пример реализации алгоритма на обучающей выборке Boston.
#предсказание столбца age обучающей выборки Boston
install.packages("randomForest")
library(randomForest)
data(Boston)
boston.rf = randomForest(age ~ ., data = Boston)
boston.rf

Рис. 6.20. Модель boston.rf
#используем пакет caret для моделирования случайного леса
library(caret)
set.seed(1)
boston.rf1<- train( age ~ ., data = Boston, method = 'rf')
boston.rf1
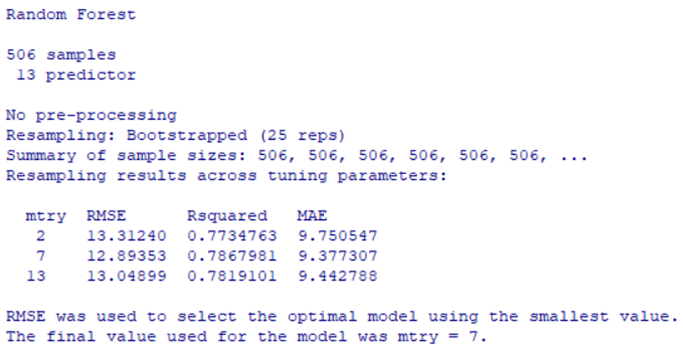
Рис. 6.21. Модель boston.rf1
#визуализация случайно выбранных параметров
plot(boston.rf1)
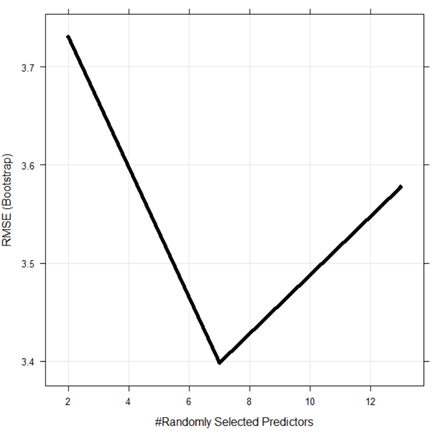
Рис. 6.22. Визуализация случайно выбранных параметров
# предварительная обработка данных перед моделированием – центрирование и масштабирование
set.seed(1)
boston.rf2 <- train( age~ ., data = Boston, method = 'rf', preProcess = c("center", "scale"))
boston.rf2
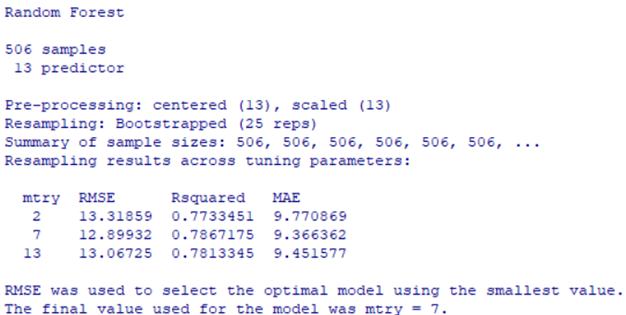
Рис. 6.23. Модель boston.rf2
plot(boston.rf2)
set.seed(1)
#делим исходный набор данных на части train-80% и test-20%
index <- createDataPartition(Boston$age, p = .80, list = FALSE)
boston.train <- Boston[index,]
boston.test <- Boston[-index,]
#подгонка модели
set.seed(1)
boston.rf3<- train( age ~ .,data = boston.train, method = 'rf', preProcess = c("center", "scale"))
boston.rf3

Рис. 6.24. Модель boston.rf3
plot(boston.rf3)
#проверка данных на тестовом наборе, вычисление RMSE, R2
boston.features = subset(boston.test, select=-c(age))
boston.target = subset(boston.test, select=age)[,1]
boston.predictions = predict(boston.rf, newdata = boston.features)
# RMSE
sqrt(mean((boston.target - boston.predictions)^2))
#значение RMSE
[1] 12.27433
# R2
cor(boston.target, boston.predictions) ^ 2
#значение R2
[1] 0.7987202
#кросс-валидация
set.seed(1)
control <- trainControl( method = "cv", number = 10,)
#переобучение модели
boston.rf4 <- train(age ~ ., data = boston.train, method = 'rf', preProcess = c("center", "scale"), trControl = control)
boston.rf4
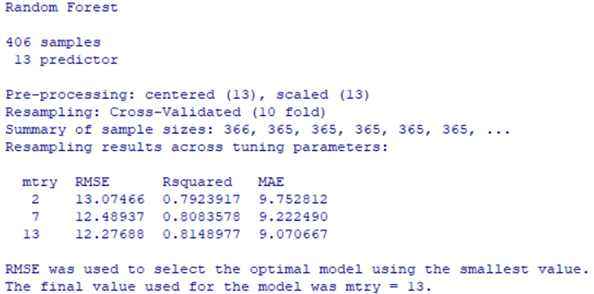
Рис. 6.25. Модель boston.rf4
plot(boston.rf4)
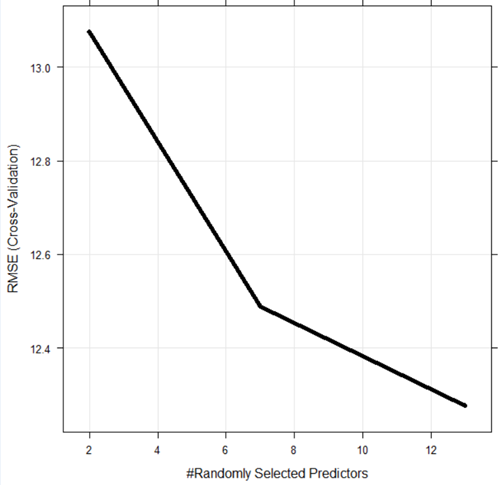
Рис. 6.26. Визуализация случайно выбранных параметров
#проверка качества обученной модели
boston.features = subset(boston.test, select=-c(age))
boston.target = subset(boston.test, select=age)[,1]
boston.predictions = predict(boston.rf3, newdata = boston.features)
# RMSE
sqrt(mean((boston.target - boston.predictions)^2))
#значение RMSE
[1] 55.11574
# R2
cor(boston.target, boston.predictions) ^ 2
#значение R2
[1] 0.2655696
#настройка модели случайного леса
set.seed(1)
tuneGrid <- expand.grid(mtry = c(2:4))
boston.rf5 <- train( age ~ ., data = boston.train, method = 'rf',preProcess = c("center", "scale"),trControl = control,tuneGrid = tuneGrid)
boston.rf5
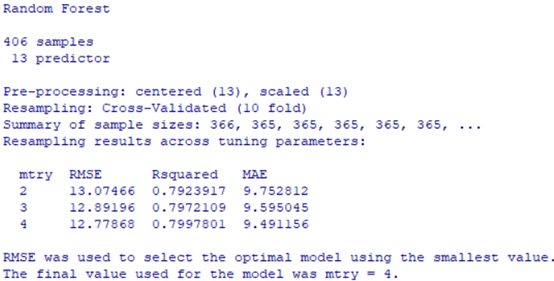
Рис. 6.27. Модель boston.rf5
plot(boston.rf5)
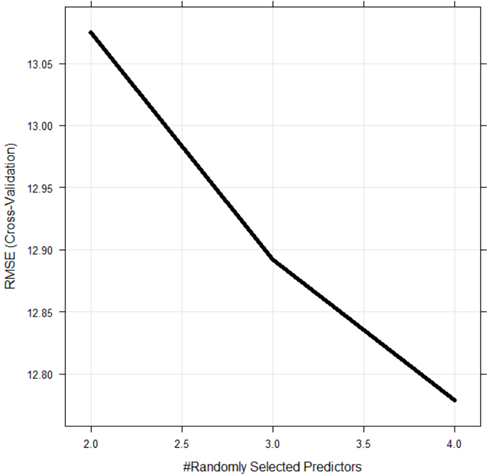
Рис. 6.28. Итоговая визуализация случайно выбранных параметров